
Agentic Evaluation for Email AI: Beyond Prompts, Toward Systems
I Thought Prompts Mattered The Most. Building Email AI Proved Me Wrong
How I went from prompt-tweaking to a full evaluation pipeline with rubric-based scoring, LLM-as-judge, and Langfuse observability and why none of it started with prompts.
I Started With Prompts. Most Engineers Do.
When we began building Email AI the early wins came from system prompt iteration. Write a better prompt, tweak tone, test outputs, repeat. And for a while, that worked, emails looked better, and responses felt "good enough."
But then something strange happened. The system didn't break. My confidence in it did.
In production, things felt inconsistent:
Some outputs were great
Some were slightly off
Some quietly failed in ways that were hard to articulate
The worst part? I couldn't measure what was going wrong. That's when it clicked:
The problem isn't generating good output. The problem is knowing at scale whether your system is actually good.
The Realization: This Is a Systems Problem
Digging into agentic patterns and evaluation research made one thing clear modern AI systems are not prompt problems. They are system design problems. The real leverage sits in everything around the model call:
Evaluation harnesses
Rubric-based scoring
Production observability
Feedback loops that actually close
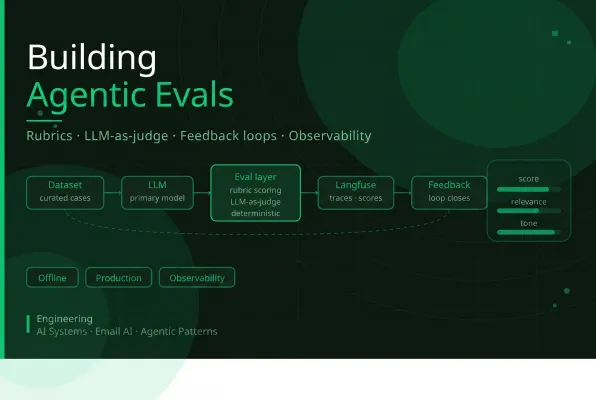
This realization shaped the architecture we ended up building: a three-layer eval system covering offline evaluation, production sampling, and a structured feedback loop all instrumented through Langfuse.
Layer 1: The Offline Eval Harness
The first layer is where quality gets defined. Before measuring anything in production, you need a reproducible baseline.
The flow

The dataset feeds a prompt builder that assembles the full context user intent, prior interactions, CTA type. The model generates a response. Then the eval layer runs three checks in sequence.

Why three evaluation methods?
Deterministic checks catch objective failures, things that should never depend on taste or interpretation. These are the fast, cheap guardrails in the eval stack. For Email AI, examples include:
Missing required elements (unsubscribe link, sender signature, footer, or CTA button)
Broken output structure (malformed HTML, invalid JSON, or missing fields)
Responses exceeding hard constraints (subject line length, character limits)
Formatting regressions (empty sections, unresolved placeholder variables)
Policy/compliance failures (forbidden claims, missing disclosures)
Action correctness (e.g., returning English when Spanish was requested)
The advantage of deterministic checks is that they provide binary answers to binary problems. If the JSON is broken, the response has already failed. These are reliable, cheap, and catch regressions before subjective quality is even discussed.
Rubric-based scoring is where the real definition of quality lives. Instead of asking "does this email look good?" (which is subjective and doesn't scale), we decomposed quality into five measurable dimensions:
Dimension
What it measures
Relevance: Does the email match the user's intent?
Tone: Is the register appropriate for the context?
Personalization: Is it specific, or generic filler?
Clarity: Is the structure and language clear?
CTA effectiveness: Is the call-to-action compelling and actionable?
Each dimension is scored independently. Failures are now diagnosable, improvements are measurable, and regressions are detectable.
LLM-as-judge runs last, and critically it uses a different model than the primary Email AI model. This is intentional. A model judging its own outputs will exhibit self-consistency bias; using an independent evaluator gives you a more objective signal. The judge receives the rubric dimensions as structured criteria and returns a scored assessment with reasoning.
What Langfuse adds at this layer
Everything inputs, context, outputs, rubric scores is logged to Langfuse. For the first time, you can trace a specific failure back to exactly which rubric dimension degraded, compare runs over time, and mine low-scoring samples into new dataset entries. It turns evaluation from a one-time check into a persistent quality record.
Layer 2: The Production Eval Pipeline
Offline evals lie a little. Your curated dataset is clean, your prompts are well-formed, your intents are unambiguous. Real users are none of those things.
So we built a second layer that runs the same rubric system against live traffic without adding any latency to the user-facing path.
The flow

The key design decision: async, sampled evaluation. The user never waits. A percentage of responses are routed to an eval worker that runs in the background, applying the same rubric scoring and LLM-as-judge logic used offline.
But that percentage should not be chosen blindly. In practice, sampling works best when it is driven by risk and signal, not just randomness. A few high-value triggers are:
Negative feedback: any thumbs-down or “this missed the point” signal should be evaluated automatically
Low-confidence generations: responses where the system is uncertain, asks follow-ups awkwardly, or takes an unusual path through the workflow
New prompts, prompt versions, or model releases: fresh changes should be sampled more aggressively until they prove stable
Edge-case inputs: unusually short prompts, ambiguous requests, multilingual inputs, or requests with missing context are more likely to fail silently
A good production strategy is usually:
100% of negative feedback cases
Higher sampling for new releases or high-risk workflows
Lower random sampling for the rest of traffic
That keeps costs manageable while still giving you strong coverage where failures matter most.

Why this matters
Without production evals, you're flying blind. With them:
You can track which rubric dimension is degrading in the real world vs. in your test set
You can spot when the quality is slowly changing (we call this drift), like the tone becoming inconsistent, the emails becoming less personal, or the call-to-action (CTA) losing its effectiveness.
You can compare offline scores vs. production scores and understand the gap between controlled and real-world quality
The rubric is the connective tissue. Because the same definition of "good" applies in both environments, your offline benchmarks become meaningful predictors of production behavior.
The Gap Nobody Talks About: The Feedback Loop
At this point we had offline evals, production evals, and Langfuse observability. It looked complete. It wasn't.
User feedback was sitting unused. People were telling us:
"This email missed the point"
"This was helpful"
"The tone is wrong for this prospect"
And the system was doing nothing with it. This is the most common gap in real-world AI systems:

Closing the loop allows the system to learn from real-world failures. Every piece of negative feedback is triaged, mapped to a rubric dimension, and queued as a candidate eval case. This turns raw user frustration into a high-signal dataset that continuously improves the offline harness.

On Memory: Utility Over Similarity
One related insight from building this system: memory design matters as much as evaluation design.
The naive approach is to store full conversation transcripts and retrieve by embedding similarity. But similarity is not utility. Just because a past email is similar doesn't mean it helped.
What actually useful memory looks like:
What was the task?
What did we generate?
What was the outcome?
Did it work?
Memory should be evaluated by experience, not raw transcripts. And retrieval should optimize for outcomes surface examples that produced positive signals, not just examples that are semantically close to the current prompt.
What Langfuse Became
Langfuse started as a logging destination. It became the operational backbone of the entire eval system:
Trace debugging follow any output back to its exact inputs and context
Score analytics aggregate rubric scores across dimensions, over time, broken down by use case
Regression tracking alert when a model update or prompt change causes score degradation
Dataset building mine production traces for new eval cases, especially from failures
Without it, every quality question would still be answered by eyeballing outputs.
Key Takeaways
Rubrics turn "good" into a signal. Vague quality judgments don't scale. Decomposing quality into measurable dimensions makes failures diagnosable and improvements trackable.
Use a different model for LLM-as-judge. A model evaluating its own outputs introduces self-consistency bias. An independent evaluator gives you a more honest signal.
Offline and production evals serve different roles. Offline defines quality and catches regressions before deployment. Production reveals how the system actually behaves in the wild. You need both.
Feedback is useless unless it enters the loop. Collecting user signals is table stakes. Operationalizing those signals mapping them to rubric dimensions, converting them to eval cases is where the real leverage is.
Memory should optimize for utility, not similarity. Retrieve examples that worked, not just examples that look like the current input.
Observability is not optional. Without end-to-end tracing and score persistence, you're guessing. Langfuse (or equivalent) is load-bearing infrastructure, not a nice-to-have.
Built with Langfuse for observability and eval tracking. Eval patterns informed by awesome-agentic-patterns.
