

KnowledgeBase Vector DB Migration
From MongoDB to OpenSearch: Rebuilding Knowledge Base Retrieval for Scale, Latency, and Cost
How we migrated 54M+ vectorized knowledge base documents from MongoDB to OpenSearch, cut tail latency by 12 to 20x, reduced infra cost by 42%, and rolled it out with zero downtime.
Introduction
As usage of our AI products grew, our Knowledge Base retrieval system started to hit a wall.
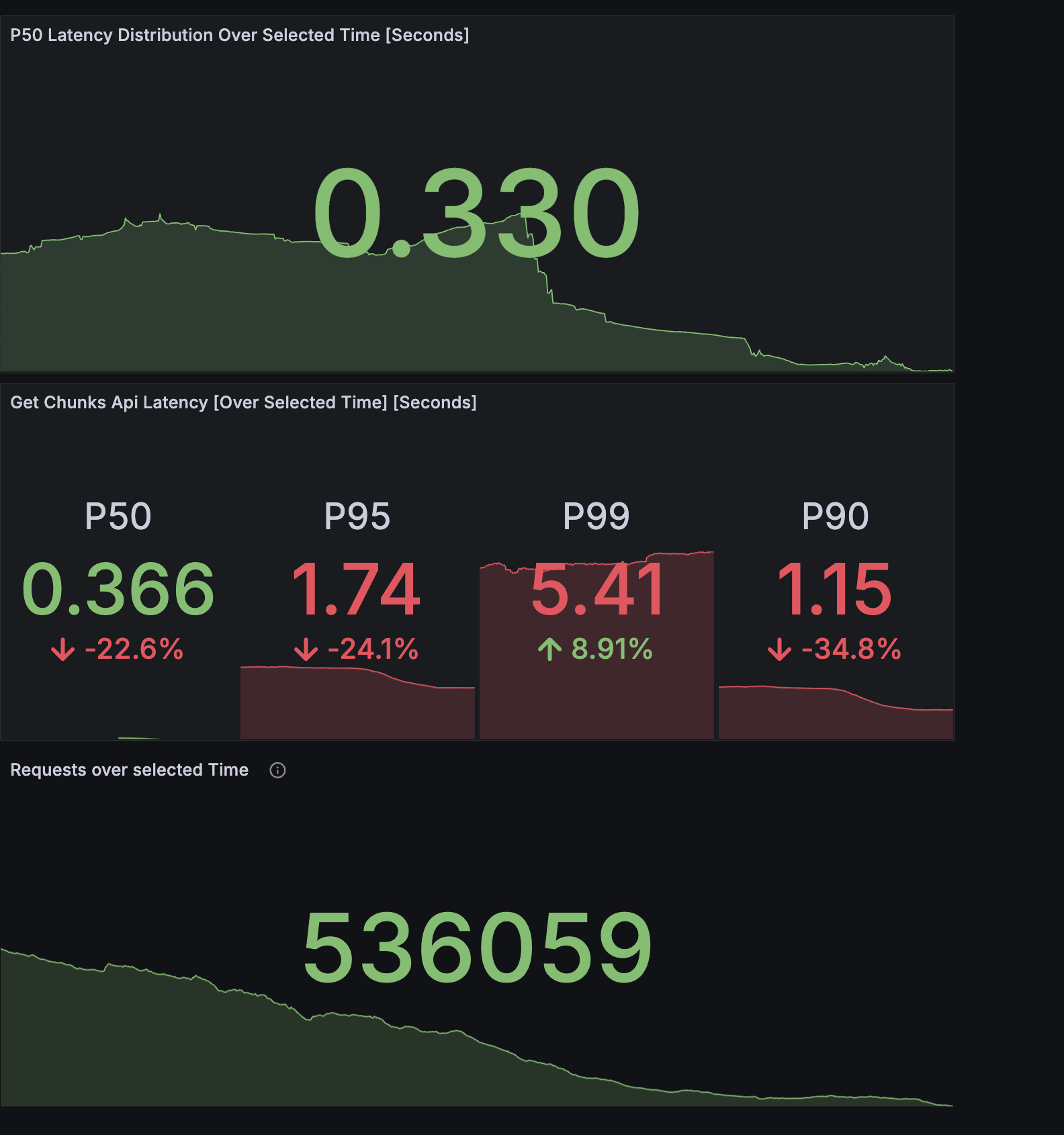
The retrieval layer powers chunk search for RAG across multiple AI experiences. At small scale, the system behaved well. At production scale, especially for large knowledge bases with tens of thousands of chunks, retrieval latency became increasingly unstable. P95 and P99 latencies regularly spiked into multi-second territory, and in the worst cases crossed 100 seconds. That kind of tail latency makes an AI system feel broken even when the average looks acceptable.
We investigated the issue end-to-end, starting from application logs and then drilling into database slow queries. What we found was consistent: the dominant bottleneck was vector retrieval in MongoDB, not embedding generation, not reranking, and not application overhead.
This post covers how we diagnosed the problem, what optimizations we tried inside MongoDB, why those optimizations were only a stopgap, and how we ultimately migrated our Knowledge Base retrieval stack to OpenSearch. The migration improved latency, reduced cost, improved stability, preserved answer quality, and gave us a more scalable foundation for future AI workloads.
Impact
After fully migrating Knowledge Base retrieval from MongoDB to OpenSearch:
54M+ documents migrated live
Zero downtime through dual-write and progressive read rollout
~42% monthly cost reduction
P95 retrieval improved from 6 to 8 seconds to under 500 ms
P99 retrieval improved from about 10 seconds to under 800 ms
~1.4 TB storage savings, primarily by excluding soft-deleted data and restructuring indexes
No measurable answer quality regression
Much more stable retrieval under large-KB workloads
The result was not just a faster retrieval backend. It was a more predictable and operationally safer system.
Why This Became a Problem
Our retrieval path serves chunk search over large knowledge bases used by AI products. Each chunk is stored with an embedding and metadata such as tenant, knowledge base, source type, and deletion state.
As the corpus grew, three things started happening together:
First, vector search latency began increasing sharply with the number of chunks per knowledge base per account
Second, deleted or inactive data continued to increase query cost and storage pressure.
Third, because retrieval sat directly in the critical path of RAG, every slow retrieval amplified user-visible latency.
The average latency was not the real problem. The real problem was the tail. A small number of large, slow knowledge bases were dominating P95 and P99 behavior and consuming disproportionate CPU, memory, and I/O.
What We Observed
We analyzed two independent datasets to understand the issue from both the API and database sides.
Dataset A: Service Telemetry Analysis
We analyzed anonymized retrieval telemetry and response timing metadata across production workloads.The analysis focused on retrieval latency patterns, response timing, and knowledge base scale characteristics.
The first major signal was simple: chunk retrieval latency was almost equal to total request latency. That immediately narrowed the search space. Retrieval was the problem.
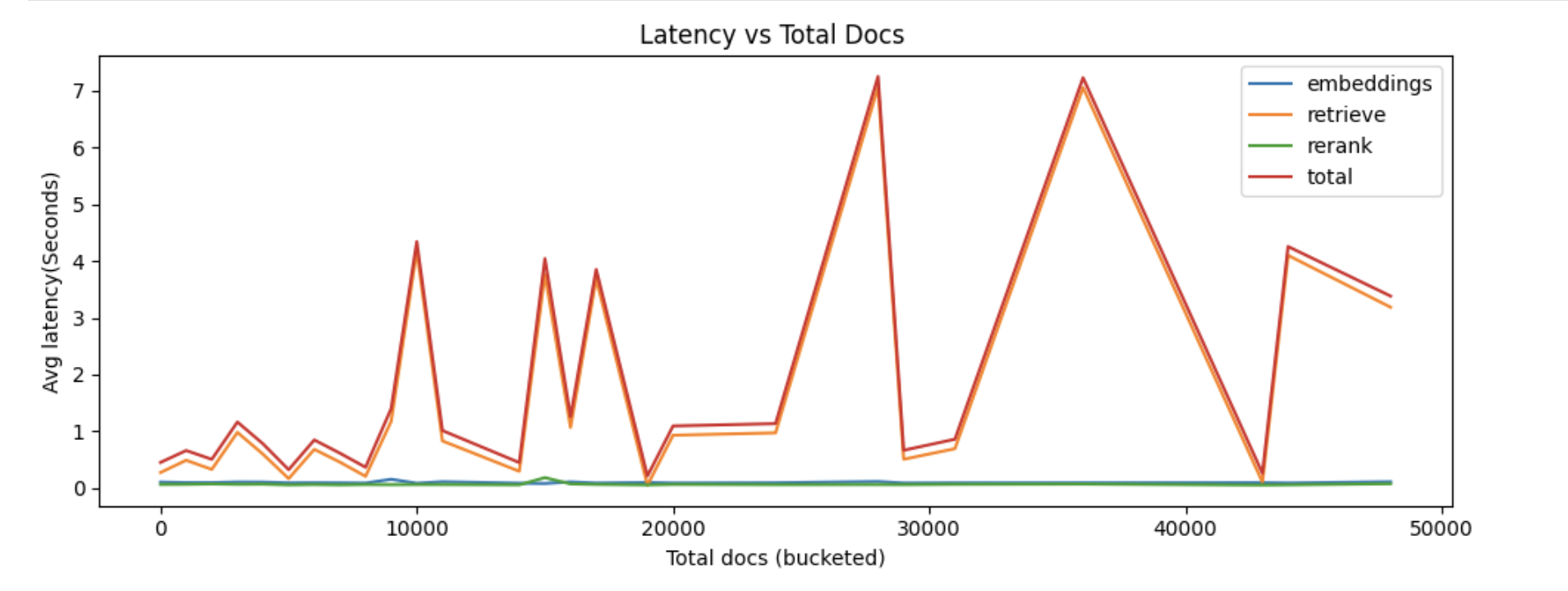
We then correlated chunk count with latency and saw a clear directional trend: [Ref. Img3]
around 100 documents[1 Document = 1 Chunk] typically stayed around ~0.5s
around 5,000 documents often moved to ~1 to 2s
30,000+ documents frequently escalated into 20 to 30s territory
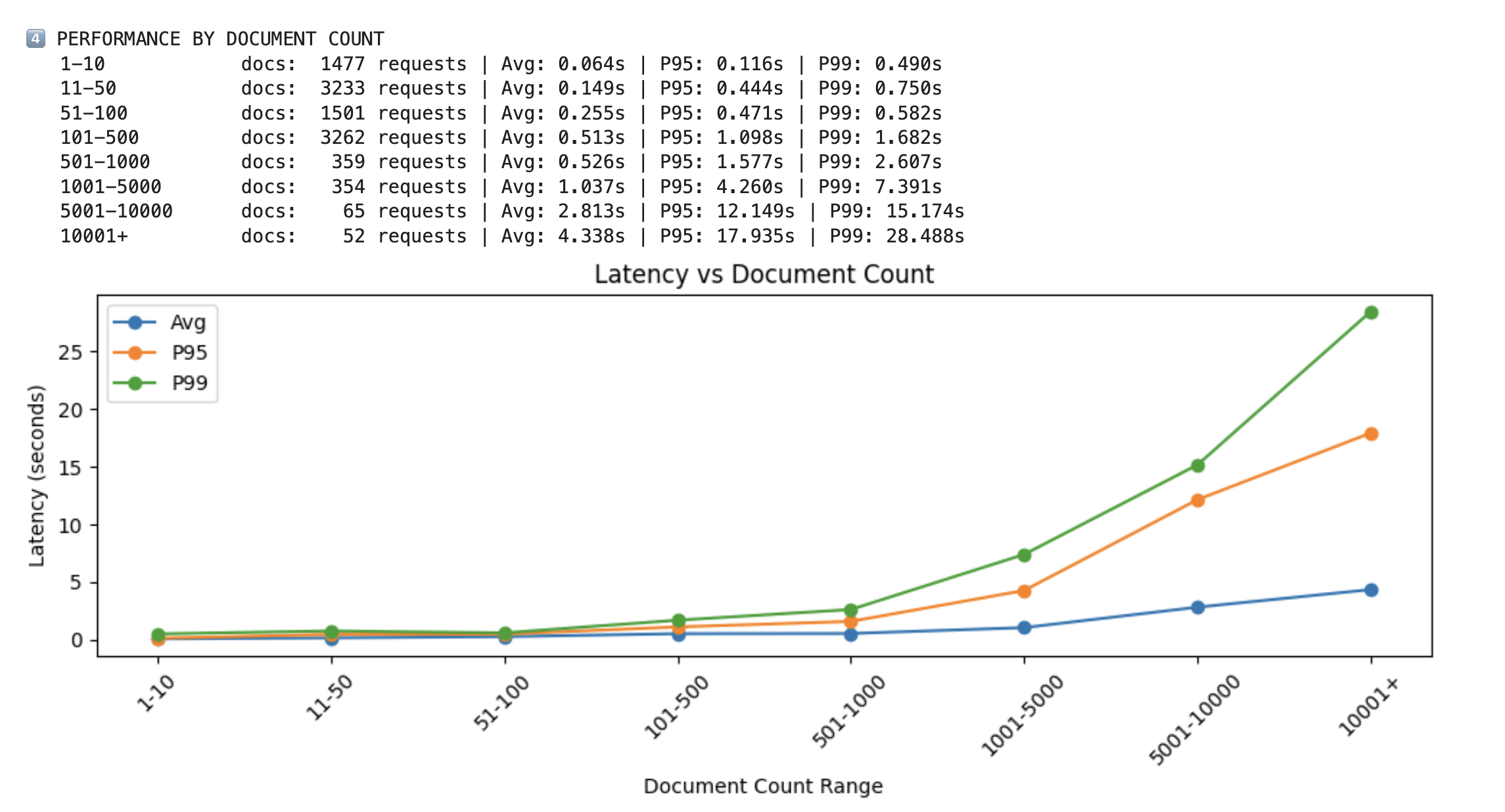
The relationship was not perfectly linear, but it was strong enough to matter.
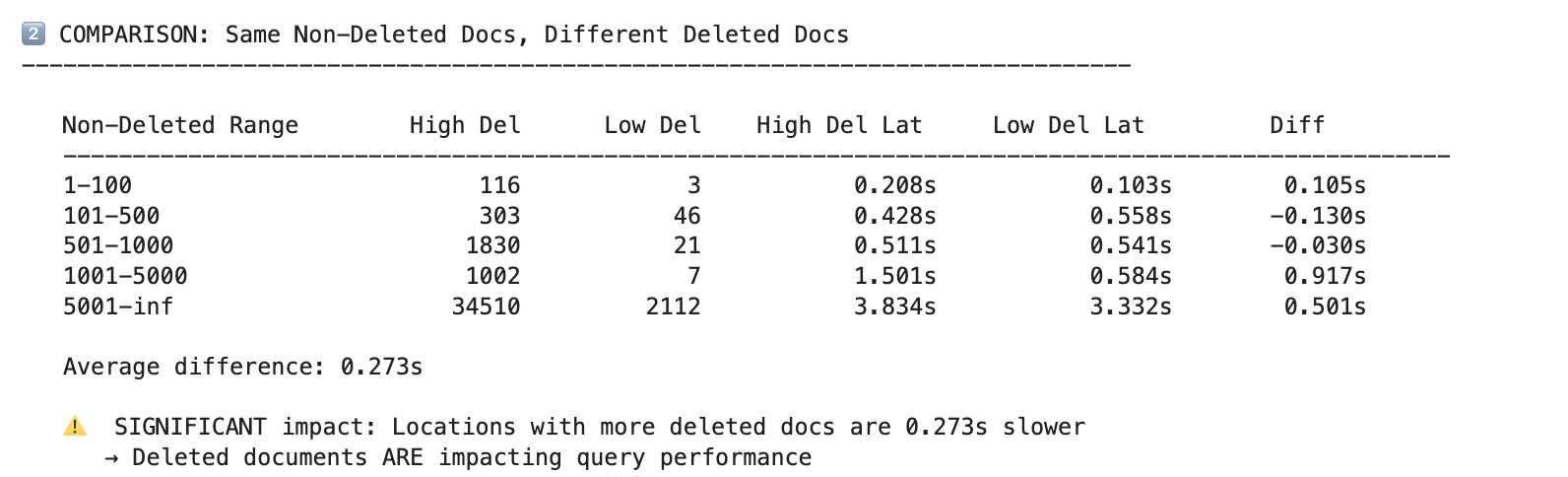
We also found that knowledge bases with more deleted documents were slower even when the count of non-deleted documents was similar. That suggested deleted records were still contributing to query cost.
Dataset B: MongoDB Slow Query Logs
We separately analyzed MongoDB slow queries, focusing on queries taking more than 500 ms.
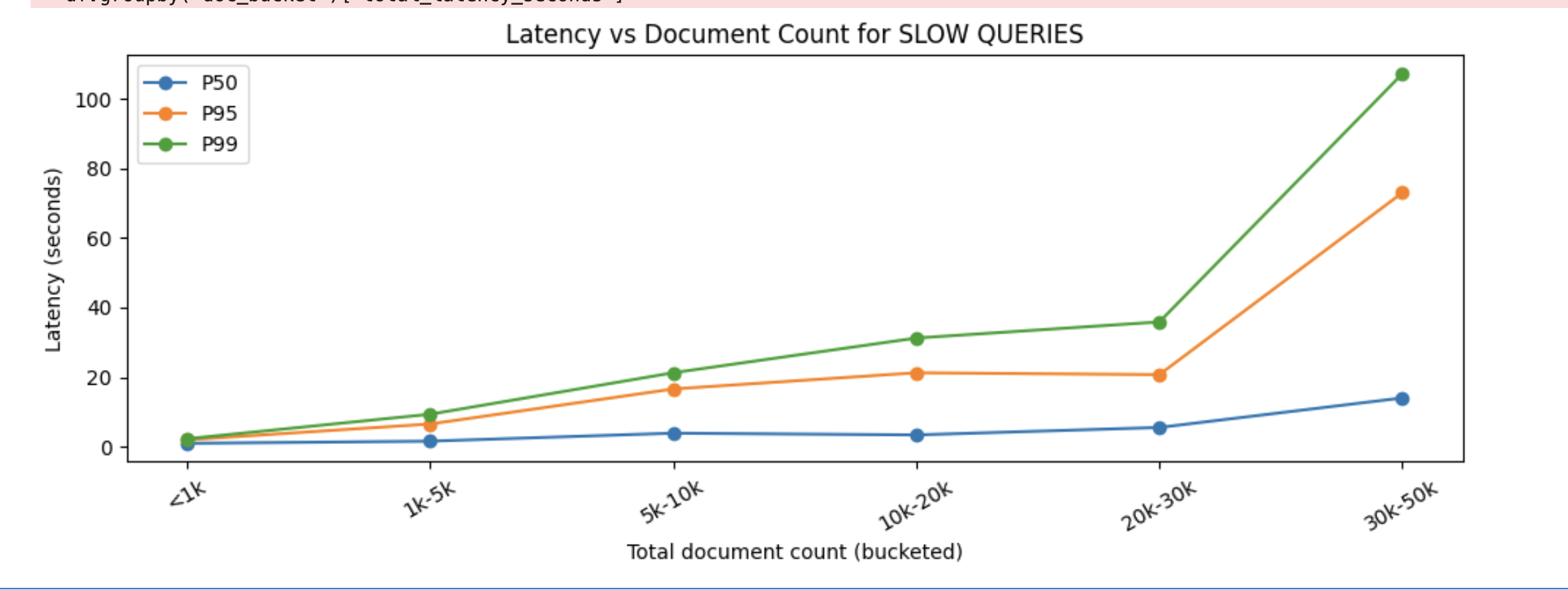
This confirmed the same pattern from the database side:
large collections produced the worst latencies
the worst slow queries aligned strongly with large KB + location datasets
P99 exceeded 100 seconds in extreme cases
At that point it was clear the problem was inside MongoDB vector search execution, not in surrounding application logic.
Breaking Down the Latency
To avoid guessing, we decomposed end-to-end retrieval into components:
query embedding
vector retrieval
reranking
response assembly
The result was decisive: roughly two-thirds of total request time was spent in retrieval. In slow cases, retrieval dominated even more.
That shaped the rest of the investigation. We did not need cosmetic API tuning. We needed to fix the data layer.
Root Cause Analysis
The bottleneck was not one thing. It was the interaction of multiple structural issues.
1. Vector search on a single massive MongoDB shard
The existing setup effectively ran vector retrieval on a single large shard containing data for many tenants and knowledge bases. Even when a request targeted a specific tenant and KB, the vector infrastructure still had to operate under the constraints of a very large shared corpus and its associated index structures.
As data volume grew, this created both latency instability and infrastructure pressure.
2. Query shape did not match the available compound indexes
We had indexes on individual fields
But the actual query path required filtering by a combination closer to:
Without a matching compound index for the filter shape, MongoDB was forced into less efficient scans around vector search and metadata filtering.
3. Deleted documents still increased cost
Deleted and inactive chunks were not free. They inflated storage, memory pressure, and the amount of data the system needed to reason about. Even when filters excluded them logically, their presence still contributed operational overhead.
4. Storage and memory pressure were already high
The MongoDB cluster was already under load from both storage and in-memory index demands. That reduced headroom for scale and made performance more fragile.
5. Tail latency amplified cluster instability
Large knowledge bases were not necessarily the majority of traffic, but they dominated cluster pain. A relatively small number of large requests drove massive spikes in P95 and P99 and consumed outsized resources.
An Optimization We Tried That Backfired
One of our early hypotheses was that MongoDB might not be exploring enough candidates during vector search, so we experimented with increasing numCandidates.
We tested both gradual and aggressive increases.
The result was the opposite of what we wanted.
Increasing numCandidates simply forced MongoDB to evaluate more vectors per request. For example:
numCandidates = 100means Mongo evaluates 100 vectors and returns the top results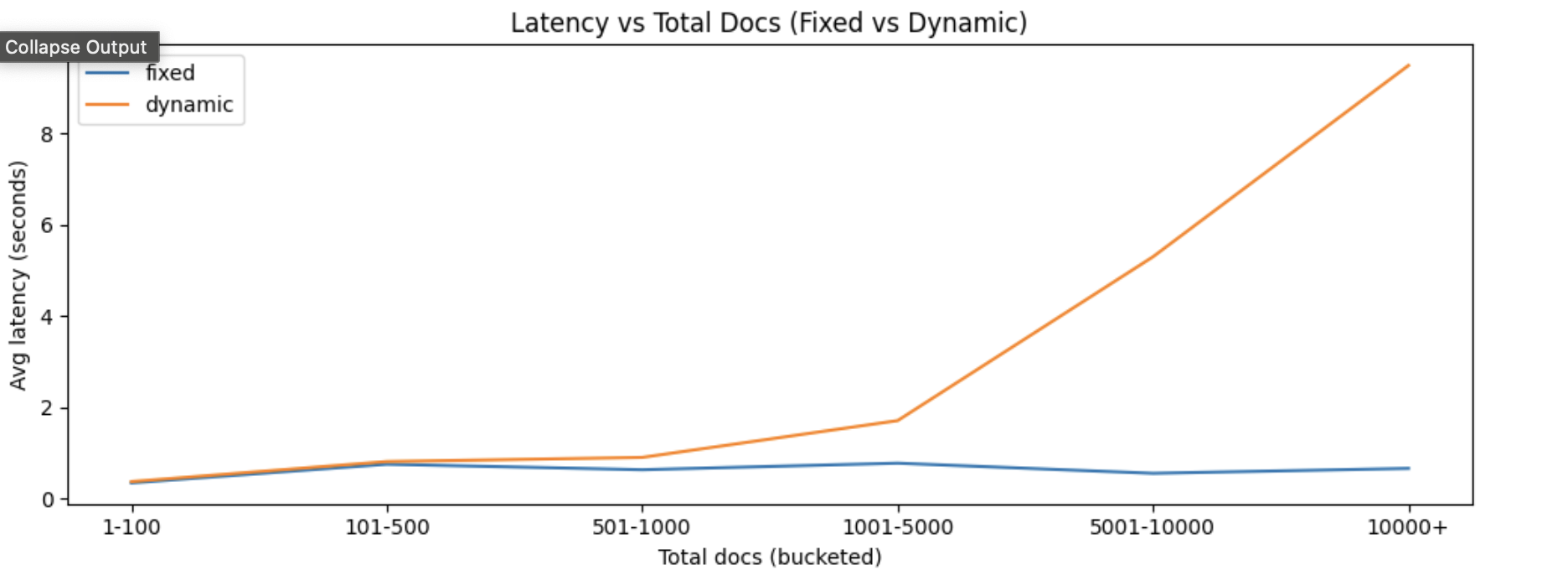
numCandidates = 2000means Mongo evaluates 2000 vectors and still returns the same top-K window
That created far more work in the slowest stage of the pipeline. Instead of reducing latency, it amplified it.
This was an important correction in our reasoning: our problem was not insufficient candidate exploration. Our problem was too much expensive vector work happening on the wrong storage and indexing model.
MongoDB Quantization as a Stopgap
Before deciding on a long-term migration path, we also evaluated MongoDB vector quantization as an intermediate option.
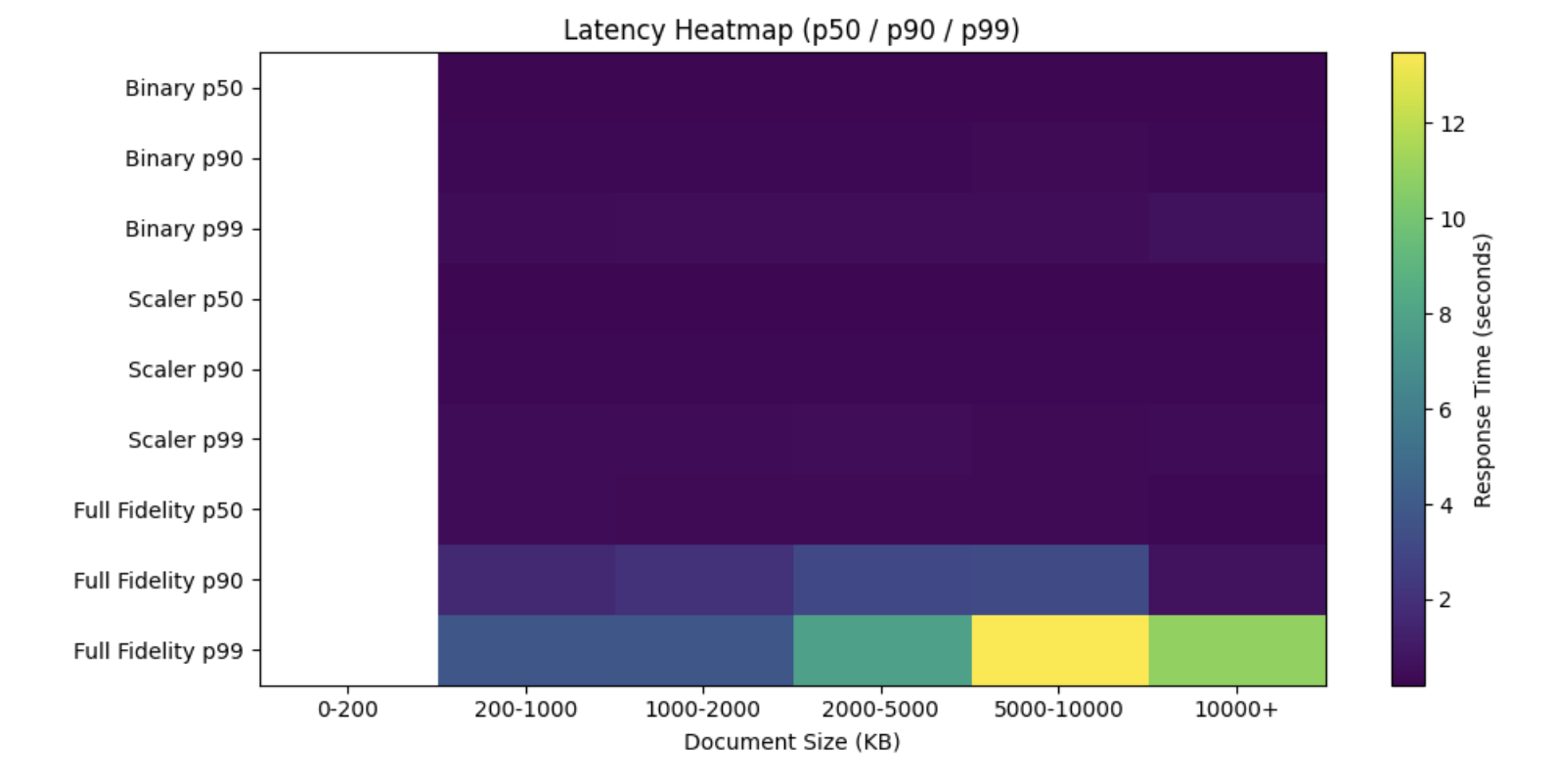
We benchmarked three configurations on a representative large dataset:
Full Fidelity
Scalar Quantization
Binary Quantization
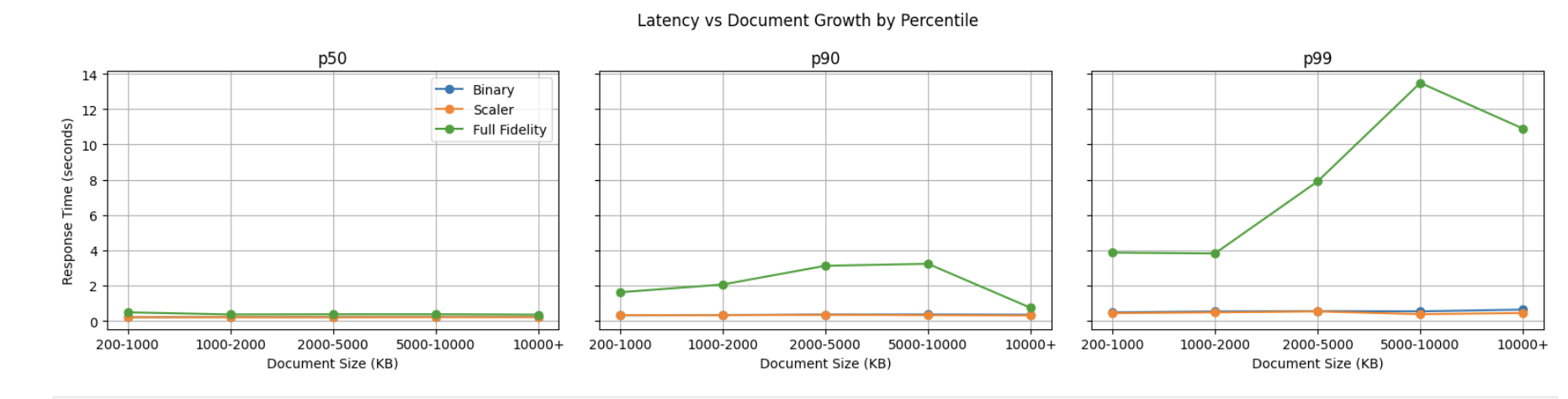
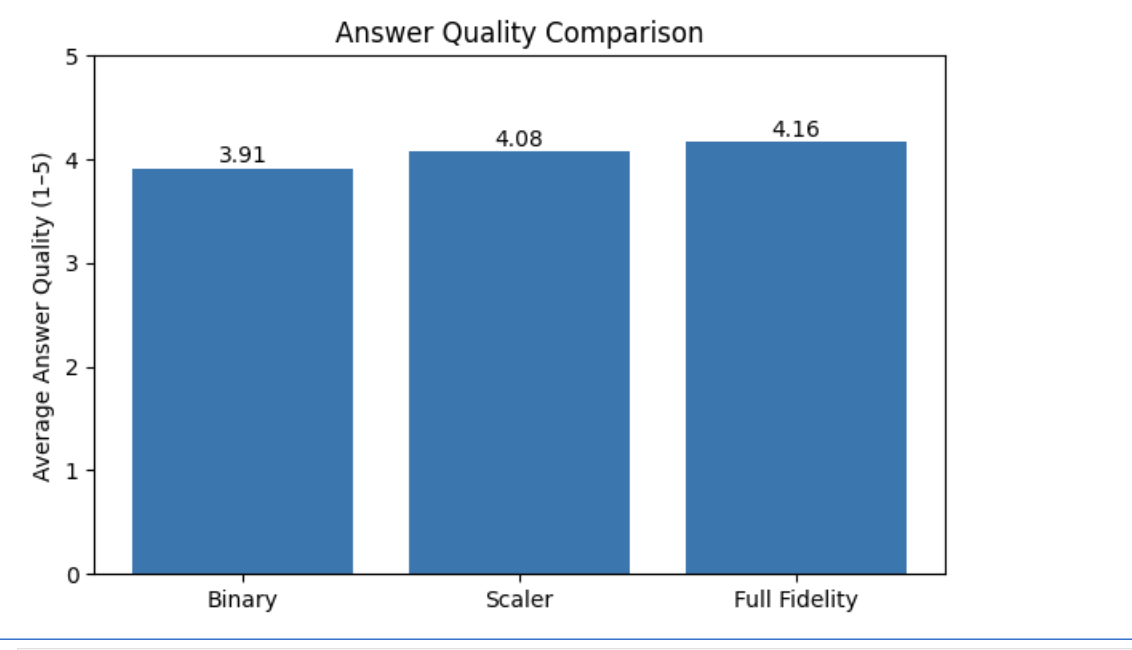
The findings were useful.
On a large KB with roughly 48K documents, quantization reduced memory dramatically and improved latency significantly. Scalar quantization preserved answer quality much better than binary, while still delivering major performance gains.
On a golden evaluation dataset:
answer quality across all three remained close
binary and scalar were much faster than full fidelity
full fidelity showed large tail spikes
retrieval, not reranking, remained the dominant source of latency
On a slow-query dataset:
Binary had the lowest quality
Scalar stayed much closer to full fidelity
Scalar and Binary both had much better tail latency than full fidelity
This gave us two conclusions.
First, Scalar Quantization was viable as a short-term operational relief valve inside MongoDB.
Second, even with quantization, MongoDB still did not look like the right long-term foundation for the workload we were building.
Quantization could buy us breathing room. It could not solve the broader architectural limits around vector-native indexing, sharding strategy, and long-term scale.
Why We Chose OpenSearch
Once we accepted that retrieval was fundamentally the issue, the next question was whether to keep pushing MongoDB or move to a system designed more explicitly for large-scale vector search.
We chose to evaluate OpenSearch because it offered three things that matched our workload well.
Purpose-built vector search
OpenSearch gives us first-class vector indexing with ANN support through Lucene and Faiss-backed approaches. That gives much more direct control over search behavior and storage tradeoffs than MongoDB’s vector abstraction.
Better sharding and routing model
Our workload has a natural partition key basis sub accounts. That matters. Instead of forcing one shared vector index to absorb all tenants equally, we could route queries toward the relevant shard. That isolates work, improves locality, and reduces unnecessary fanout.
Better long-term storage and quantization options
OpenSearch gives us more freedom around vector representations, compression, and future optimizations. That matters because our corpus is not static. It grows continuously and powers multiple AI products.
Our OpenSearch POC
We first ran a benchmark on a controlled dataset to validate both latency and answer quality before attempting full migration.
Dataset
around 243 slow-performing locations
500 evaluation queries
Systems compared
MongoDB Atlas vector search
OpenSearch Standard, single shard
OpenSearch Routed, 5 shards with workload-aware routing
Results
Average retrieval latency:
MongoDB: 235 ms
OpenSearch Standard: 248 to 295 ms depending on run setup
OpenSearch Routed: 184 ms
The main result was not “OpenSearch is always faster.” The more important result was:
OpenSearch with the right shard routing was clearly faster than both MongoDB and non-routed OpenSearch.
That proved something important for production design: sharding and routing strategy mattered at least as much as engine choice.
Accuracy
We also evaluated retrieval quality using relevance scoring and recall-based comparisons.
The OpenSearch configuration performed slightly better than MongoDB:
about 3.8% better relevancy
about 8.4% higher recall
That mattered because it removed the biggest migration risk. We were not trading quality for speed.
OpenSearch Architecture Choices
Once the POC was promising, we worked through engine and indexing choices for production.
Engine choice
OpenSearch supports Lucene, NMSLIB, and Faiss-backed k-NN paths.
For our workload, Faiss-backed HNSW was the best long-term fit because it provides:
better control over ANN tuning
quantization options such as FP16
better flexibility for future scale and performance work
Method choice
We compared HNSW vs IVF conceptually and operationally.
For our workload: (Reference)
recall mattered more than extreme compression
operational simplicity mattered
training-heavy IVF tradeoffs were unnecessary
So we selected HNSW.
Parameter profile
We converged on a balanced HNSW profile: (Reference)
m = 16ef_construction = 128ef_search = 128
This gave a strong balance between recall, memory growth, and latency stability.
Quantization
For OpenSearch, FP16 scalar quantization was the most practical next optimization: (Reference)
meaningful memory reduction
minimal quality loss
lower complexity than aggressive PQ strategies
This lined up with both our Mongo quantization learnings and OpenSearch’s own vector storage model.
Migration Strategy
A direct cutover would have been reckless, which is a very popular engineering hobby until production starts burning.
We instead used a staged migration model built around safety and reversibility.
Phase 1: Dual-write
We introduced dual-write so newly ingested or updated chunks were written to both MongoDB and OpenSearch. This ensured index freshness and created a rollback path.
Phase 2: Progressive read rollout
We gradually shifted read traffic to OpenSearch while validating:
latency
answer quality
index health
operational behavior on live workloads
Phase 3: Validation and comparison
We continuously compared OpenSearch against MongoDB using production-shaped datasets and evaluation sets, especially on previously slow knowledge bases.
Phase 4: Full cutover
Once retrieval quality and latency were validated, we moved reads fully to OpenSearch and then began decommissioning the MongoDB-based retrieval path.
This rollout let us migrate 54M+ documents live with zero downtime.
What Changed After Migration
After the cutover, the operational behavior changed in exactly the ways we wanted.
Tail latency collapsed
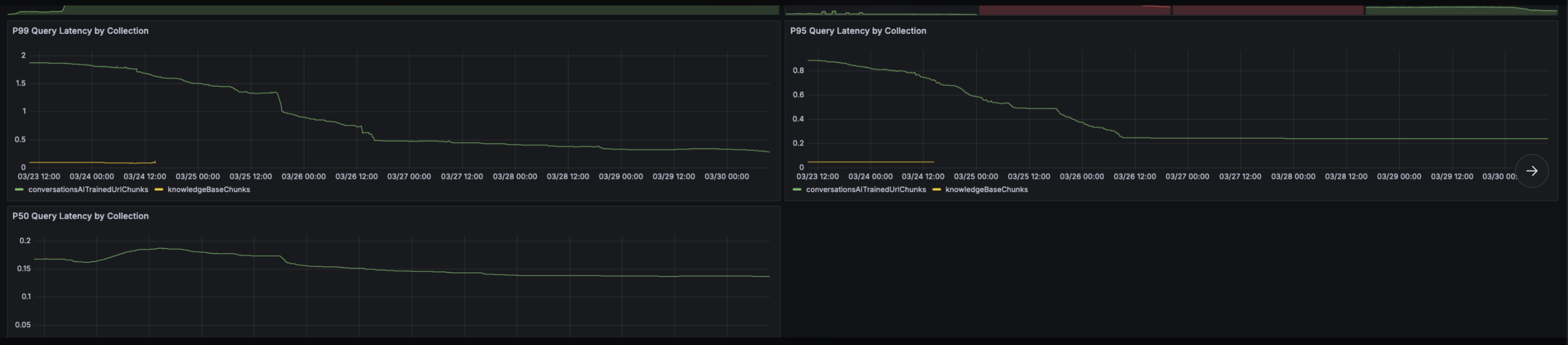
The old retrieval path routinely saw:
P95: 6 to 8 seconds
P99: around 10 seconds, sometimes much worse in pathological cases
After migration:
P95: under 500 ms
P99: under 800 ms
That is not a small improvement. It is the difference between “retrieval is the bottleneck” and “retrieval disappears into the background.”
Stability improved
Previously, large knowledge bases produced unstable tail behavior and frequent performance stress. After migration, index health stabilized and the system stopped behaving like it was one oversized tenant away from having a bad day.
Cost improved
The migration also reduced infrastructure cost by about 42%
Accuracy stayed flat
We saw no meaningful regression in answer quality after moving to OpenSearch. That was critical because faster retrieval is useless if it degrades the retrieval grounding that downstream answer generation depends on.
Why the Migration Worked
The biggest lesson from this migration is that the improvement did not come from one magic configuration.
It came from aligning the system architecture with the actual workload:
vector-native retrieval engine
routing-aware sharding
better storage behavior
safer rollout model
cleaner separation between hot data and deleted noise
better operational control over ANN tuning
MongoDB quantization helped prove that vector representation matters. OpenSearch proved that engine architecture and data partitioning matter even more.
Lessons Learned
A few takeaways stood out from the project.
1. Tail latency matters more than averages
A system can look healthy on average while still failing users badly at the tail. Large KBs were rare, but they dominated the pain.
2. Retrieval architecture matters more than downstream optimizations
We could have spent much longer tweaking reranking, concurrency, or application logic. None of those would have fixed the real problem.
3. Quantization is useful, but not sufficient by itself
Quantization bought real gains, especially scalar quantization, but it did not remove the underlying architectural limitations of the original system.
4. Routing is a first-class design decision
The OpenSearch POC made it obvious that routing was not an implementation detail. It was central to performance.
5. Live migrations need rollback-friendly rollout plans
Dual-write and progressive rollout let us move a production-critical retrieval system without downtime and without betting everything on one cutover window.
